What Is A Data Modeling Layer?

This article was originally written by Cedric Chin for Holistics.io
Most fields have trends. Some of these trends turn out to be fads, while others stick around. As a field, data analytics is no different. A thinker or a company or a practitioner introduces a new approach to an old problem, and then the idea spreads throughout the entire industry. It becomes part of the zeitgeist.
I bring this up because there seems to be a certain class of analytical tools today that are built around a small handful of core ideas. When we wrote our ‘data analytics guidebook’ (which is due any day now; we’re deep in editing hell), we struggled for a name to categorise such tools. In the end, I think we settled on something rather sensible. We called these tools ‘data modeling layers’, or — more verbosely — ‘data modeling layer tools’. We think naming them like this will make them more easily recognizable.
Today, these tools are things like dbt, Dataform, Holistics, and Looker. We expect more tools to be added to this category over time. These tools share a number of common characteristics:
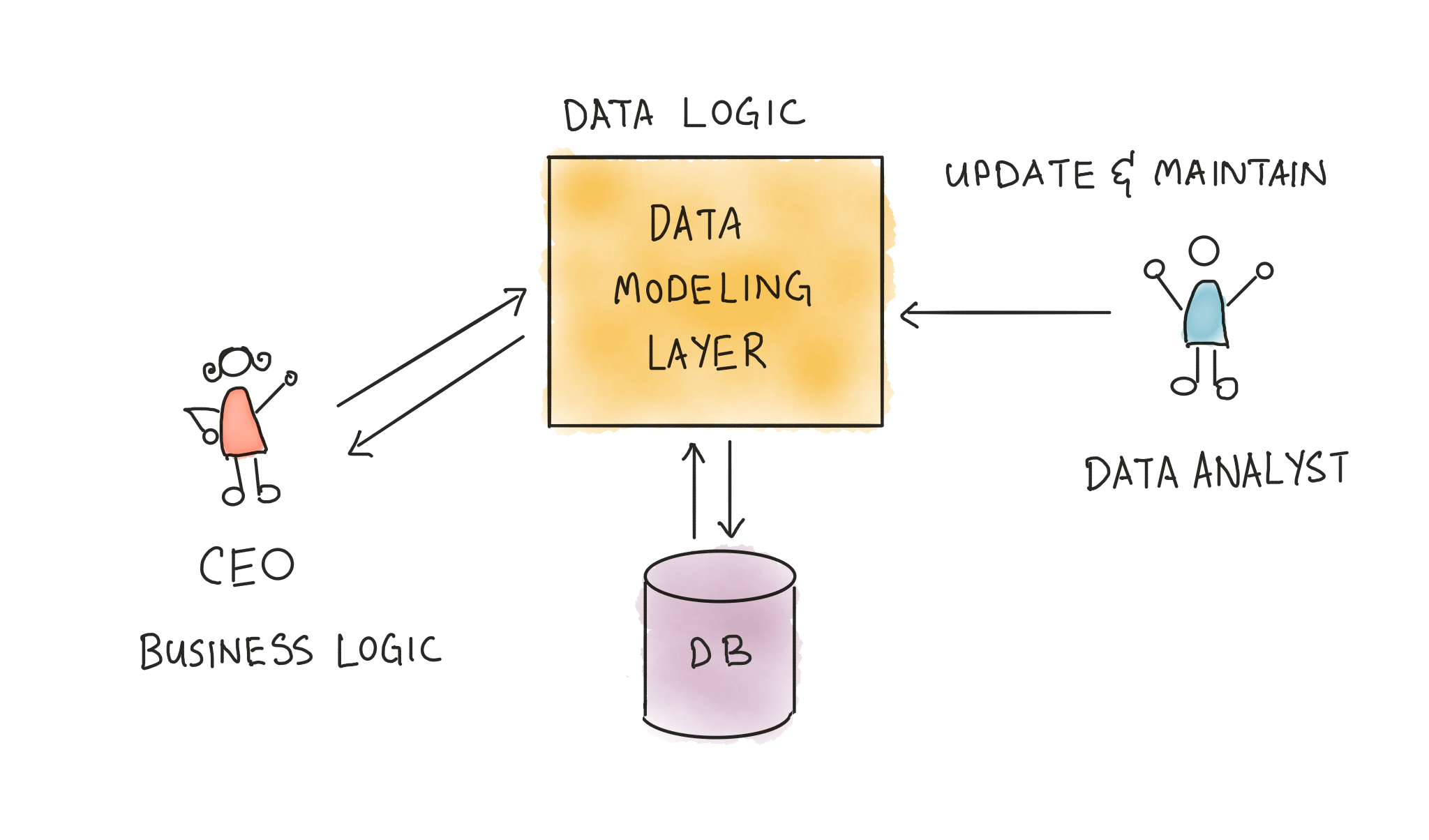
- They connect to your data warehouse.
- They treat the modeling process as the act of transforming data from old tables to new ones within the data warehouse.
- They generate SQL behind the scenes to execute such transformations.
- They allow users to annotate, manage, and track changes to data models over time.
- They allow users to trace the lineage of data transformations within the single tool … and more besides.
Conceptually, these tools act as a data modeling ‘layer’ above the data warehouse. Once you’ve connected the tool to your warehouse of choice, your data team uses said tool as the primary interface with which you do transformations, cleaning, aggregations, and dimensional modeling. You no longer touch the data warehouse directly.
Let’s do a quick tour of these tools to see what we mean by this.
Looker
Looker was arguably the first company to use (invent?) the basic ideas that are behind the current generation of data modeling layers. Connect a data warehouse to Looker, and Looker will generate a basic LookML model. (LookML is Looker’s custom modeling language). This model is an abstract object that sits only within Looker, that allows you to modify fields, augment data, or create new derived tables for the rest of your company.
Looker then encourages you to share these data models across your entire data team. To business users, it exposes a self-service interface for each model that you want shared. The point to note here is that everything happens within Looker and the data warehouse — Looker doesn’t require you to use an external pipelining tool to transform the tables it finds in your warehouse. Rather, you can extend and modify your tables using Looker itself. Looker simply generates the SQL to make those transformations happen.
dbt
dbt stands for data build tool. dbt takes many of the ideas in Looker’s modeling layer and extends it into a dedicated transformation tool. Unlike Looker, which uses LookML, dbt uses SQL directly. Every data model in dbt is essentially a SELECT statement over some set of tables in your data warehouse. You may modify this ‘view’, or create new derived models that may be persisted as tables in your data warehouse. You may also generate documentation from your models, and write assertion tests to check for model accuracy.
dbt makes transformations really easy. More importantly, as a centralized hub for data transformation and model management, it’s really easy to make dbt the central layer of truth for all the data in your organization. You are expected to use dbt as part of your existing cloud-based analytics stack.
Dataform
Dataform is similar to dbt. They have their own language for data modeling, named ‘SQLX’, that is essentially an extension of SQL to support dependency management, testing, documentation, and more.
Dataform’s functionality is drawn from the same set of ideas. The tool connects to a data warehouse and runs transformations within the warehouse itself. It allows you to do incremental table loads, write SQL unit testing, create tags for documentation, and publish datasets for consumption across your team. Uniquely amongst the other tools, Dataform has an extensible Javascript API to augment the SQL-based language it expects you to use. Like dbt, it is intended to be plugged into an existing data stack, as a layer above your data warehouse.
Holistics
Holistics’s data modeling layer is built with the same set of ideas presented above. Holistics connects to your data warehouse, generates SQL to perform transformations, and does all of its transformations within the warehouse itself. It is also able to generate and maintain models that are combinations of tables in different connected databases.
The difference here is that Holistics comes with batteries included — the tool comes a small handful of connectors to a bunch of different data sources, and the data modeling layer is deeply integrated into a self-service user interface for non-technical business users. Data analysts can switch from modeling to report creation to notification scheduling in a heartbeat.
As a result, Holistics is used in companies that want to go from zero to reporting results quickly. We’ve seen data professionals adopt Holistics alongside an MPP cloud data warehouse as the first major tool in their stack, before — later — augmenting it with other tools as they grow.
Read more: Best Open-source Data Modeling Tools For Any Data Teams
What Makes These Tools Possible?
Why are these ideas gaining traction in so many places? The answer is something that we’ve covered on this blog, multiple times in the past:
- Massively Parallel Processing (MPP) cloud-based data warehouses are powerful enough now that transformations can be done entirely through SQL, within the data warehouse. You don’t have to use a separate pipelining tool to do such transformations. This keeps infrastructure complexity down, which keeps maintenance costs down, which in turns allows you to hire less data engineers and keep personnel costs down.
- The rise in popularity of ELT (extract, then load, then transform) — which is the act of dumping all your data in a data warehouse first, before transforming it within the warehouse later — has also aided or been aided by the rise of such tools. All the data modeling layer tools assume that you’re going to do ELT instead of ETL.
- Having everything in one tool, within one warehouse, makes it easier for a data organization to deliver value. You no longer have the scenario where your data analyst waits on your data engineer for new transformed data — the analyst can simply do the transformation themselves.
It’s important, however, to not get fixated on the specific tools that we’ve discussed here. The most important idea you should take away from this piece is that there exists a distinct category of data tools that exist in the marketplace today, and that you now know what the identifying markers are. These are tools that don’t yet have a good name. You won’t see them as a distinct Gartner category. Nevertheless, these tools share a common conceptual ancestry, and are drawn from a neighbourhood of similar ideas.
We think that the phrase ‘data modeling layer’ best captures this approach, and we hope you’ll see the obvious affordances this term gives you. If you see a tool that offers to let you do data modeling, that connects to your data warehouse, and that generates SQL to do transformations and to materialize views within said warehouse, it’s likely that you’re looking at tool that inherits from this approach.
There’s a good argument to be made that over time, all of data analytics will eventually move to this approach. But until that happens (or doesn’t happen!), the term ‘data modeling layer’ will probably be a useful phrase to delineate between the tools that use this approach and the tools that don’t.